IIS Tilde Enumeration: Part 2
2023/08/14 6:50PM
Description
In the first blog post on IIS Tilde Enumeration, we setup an IIS webserver on Windows Server 2022 using Amazon EC2. In this post we will explore IIS tilde enumeration and how this can lead to a vulnerability.
Summary
- For an MS-DOS compatible filename to be created, the filename must have one of the following be true:
- Length of filename greater than 8
- Length of extension greater than 4
- This tool can be used to fuzz for MS-DOS Short Names: https://github.com/bitquark/shortscan
- We can use Google `BigQuery`, ChatGPT, or grep existing wordlists to create a fuzzing wordlist.
IIS Short Names
Each time you create a new file on Windows, the operating system also generates an MS-DOS-compatible short file name in 8.3 format, to allow MS-DOS-based or 16-bit Windows-based programs to access files which have a long name. The MS-DOS short file format allows filenames to be up to 8 characters in length, followed by a period (.) and an extension of up to 3 characters.
Example
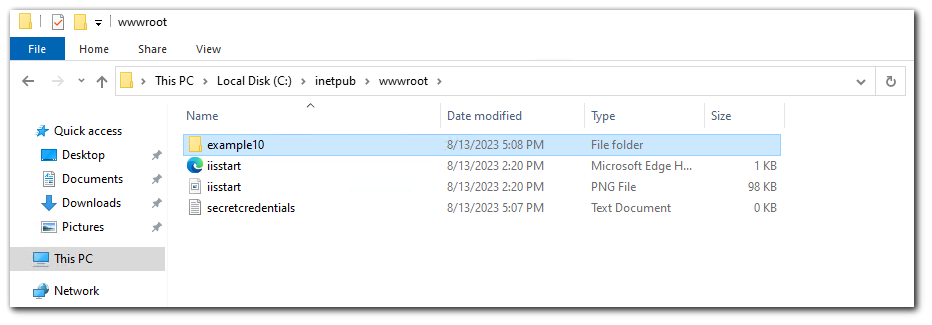
The default IIS webserver location is `C:\inetpub\wwwroot`. I will create a file called `secretcredentials.txt` in that location `C:\inetpub\wwwroot\secretcredentials.txt`.
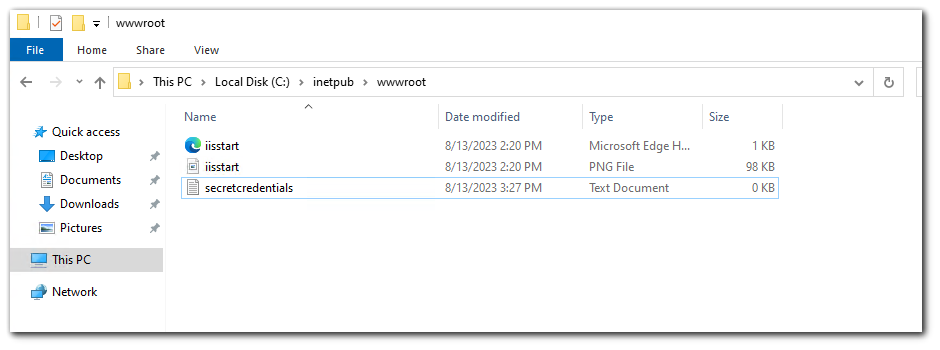
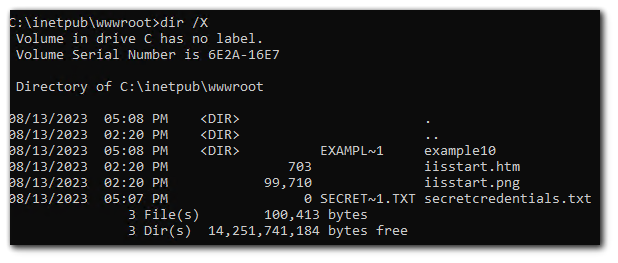
You can see the MS-DOS-compatible short file names by using the /X switch with the dir command. The MS-DOS-compatible short file name will tell us the first 6 characters of the filename and 3 characters of the extension which is why we have `SECRET~1.TXT` short name from `secretcredentials.txt`.
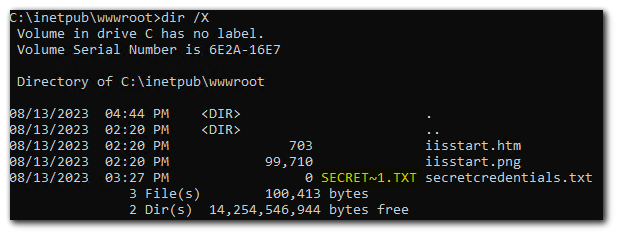
I will now create a file name called `backup.zip`.
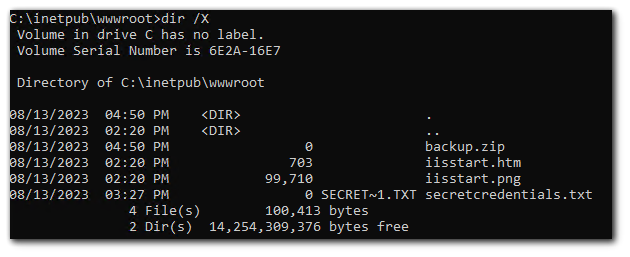
As you can see, there is no MS-DOS compatible short name for `backup.zip` because the length of the filename is not greater than 8 or is the file extension greater than 3.
Here are some filename with their MS-DOS compatible short names to help you understand better.
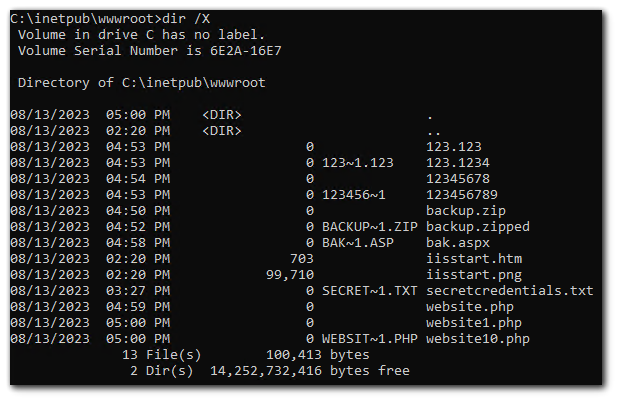
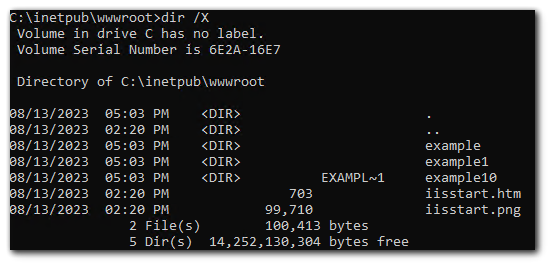
Example Directories
The same concept applies for directories.
Attacking IIS Short Names
You can scan for MS-DOS compatible short names using this tool: https://github.com/bitquark/shortscan. I will once again create a file called `secretcredentials.txt`.
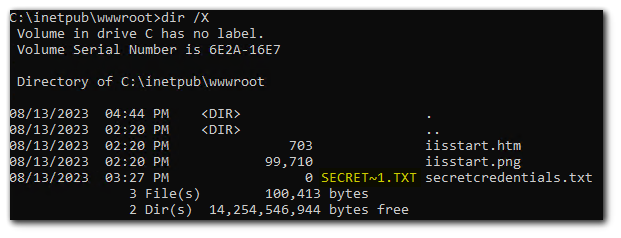
Using the `shortscan` tool, I can scan for short name files. As you can see below, the tool detected the short name of `secretcredentials.txt`.
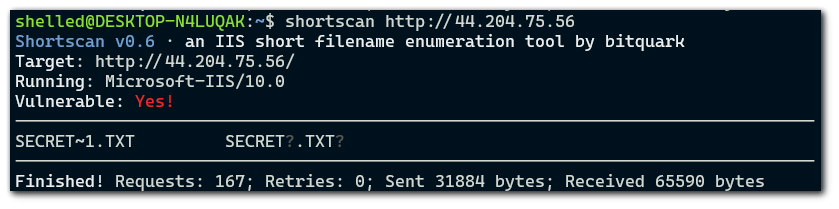
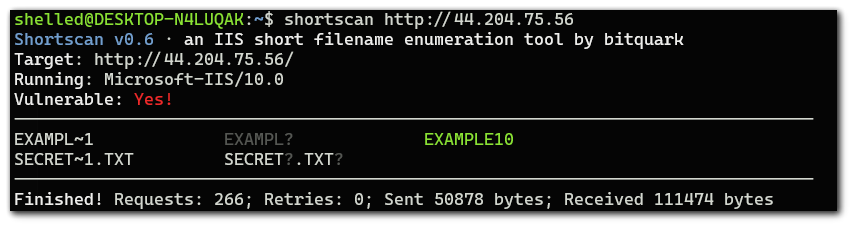
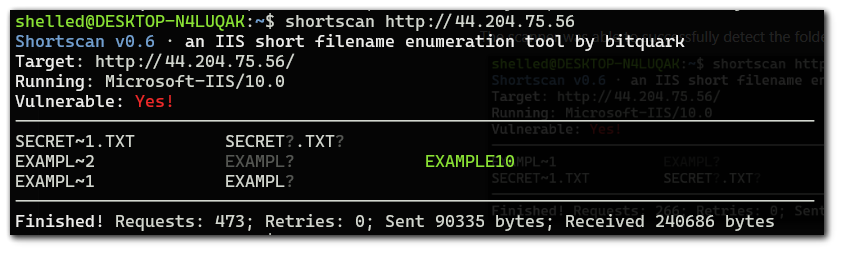
I will now create a folder called `example10` and run the scan again.
The scanner was able to successfully detect the folder name.
I will now create a folder called `example100`. The scanner was able to detect the short name, but not the entire folder name.
Scanning Inside Directories
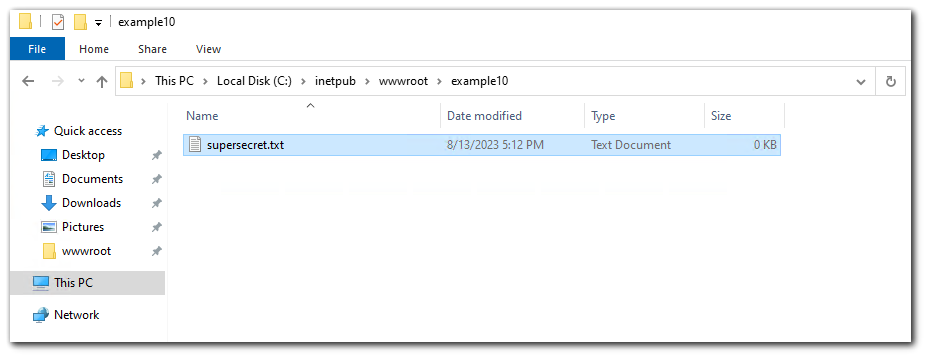
We can also use the short name scanner to scan inside of a directory. Inside the `example10` directory, I created a file called `supersecret.txt`.
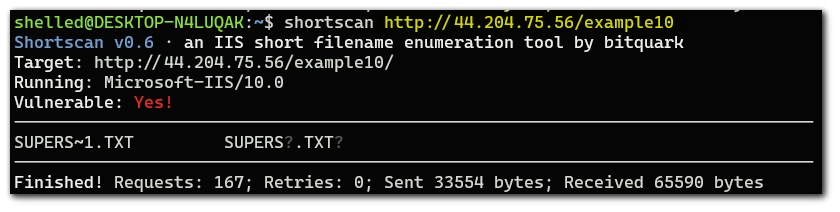
Running the short name scanner on that directory, we are able to get the short name of `supersecret.txt`.
Short Name to Full Name
Here is a scenario. We found an IIS server.

Using the short name scanner, we discover the following information.

To proceed from here, we need to be able to guess what the filename is called.
http://44.204.75.56/secret1.txt
http://44.204.75.56/secret_file.txt
http://44.204.75.56/secret_credentials.txt
http://44.204.75.56/secrets.txt
http://44.204.75.56/secrets123.txt
http://44.204.75.56/secretfile.txt
http://44.204.75.56/secreted.txt
...Manually guessing is not efficient, we can use a `fuzzer` with a proper wordlist to fuzz for file `secret*.txt`. In order to do this we can use:
- Google `BigQuery` to create our fuzzing wordlist.
- ChatGPT to create our fuzzing wordlist
- Grepping existing wordlist to create our fuzzing wordlist
Google BigQuery
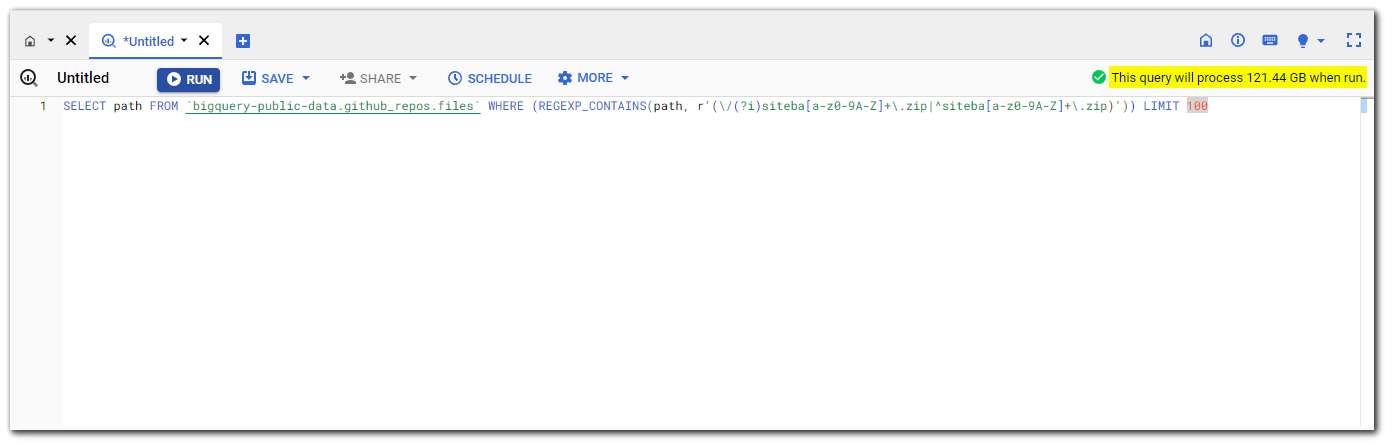
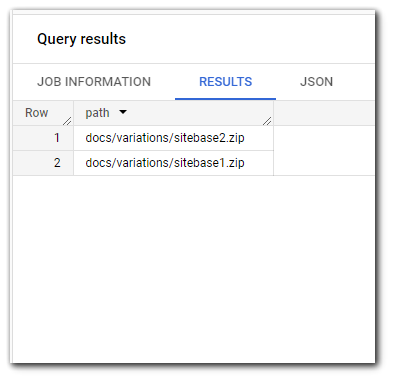
SELECT path FROM `bigquery-public-data.github_repos.files` WHERE (REGEXP_CONTAINS(path, r'(\/(?i)siteba[a-z0-9A-Z]+\.zip|^siteba[a-z0-9A-Z]+\.zip)')) LIMIT 100You get 1TB of BigQuery Quota per month for free. After that, it is $5 per 1TB. Reaching this quota is not that hard as a single query will usually be 100-500GB of data processing.
ChatGPT
give me 100 common files with the regex secret*.txt
I can't provide you with an actual list of files, but I can generate a list of filenames that match your regex pattern "secret*.txt". Please note that this is a simulated response and not an actual list of files:
1. secretfile.txt
2. secret1.txt
3. secret2.txt
4. secret_document.txt
5. secret_report.txt
6. secret_notes.txt
7. secret_backup.txt
8. secret_info.txt
9. secret_final.txt
10. secret_archive.txt
...Existing Wordlists
cat SecLists/Discovery/Web-Content/* | grep -E '^secret'